
《汉字转拼音的浏览器端实现》原文:https://zhuanlan.zhihu.com/p/29813596?utm_source=qq&utm_medium=social
这篇文章里的方法论有问题、实现过程有问题、结论也有问题。
看到这篇文章的时候,让我想起了当年写ASP的日子。现在还可以找到《ASP获取汉字拼音(使用Scripting.Dictionary)》这篇文章:http://blog.csdn.net/wlwqw/article/details/1810601
注意《ASP》一文内的以下两行代码:
dic.add "a",-20319
dic.add "zuo",-10254我们知道:
-20319 是 B0A1 的十进制补码表示,-10254 代表 D7F2。
ASP 是运行于 Windows 平台的。
中文 Windows 下,ANSI 编码使用实际使用 GB18030 / GBK / GB2312 (根据操作系统版本决定,但都兼容 GB23121)编码保存。
GB2312 编码表中,16区从 B0A0 开始,55区的结束位置是 D7FF 2。
GB2312 的 16-55 区为一级汉字,按拼音排序,共有 3755 个字。
正是受益于GB2312的设计,才能以简短的代码实现拼音排序。如果我们输入的是 GB2312 的二级汉字,或者是 GB18030 里的其它汉字,或者干脆用 UTF-8 输入一个汉字,这份代码就查不出其拼音了。
回到JavaScript。JavaScript 中的中文字符是以 UTF-16 编码保存的,所以通过比较 UTF-16 存储的位置就可以了吗?答案是当然不可以了。仅以文章中的“网易公司”四个字的“网”字为例,其 UTF-16 编码是 7F51,但 7F50 是“罐”,7F52是“罒”。这一些文字在Unicode的中日韩统一表意文字区域(4E00 – 9FEA),置放于基本多文种平面;它们的排序顺序是依照康熙字典的部首/笔画顺序3。所以,需要文章里说的localeCompare。
于是,我们回到了《汉字》原文。
先吐槽一个点:
还有比如“谁”,浏览器把它排在了“shei”区块,但我们一般念“shui”,这个字更加特殊,因为只有这么一个字念“shei”,所以可以把“shei”这个读音从映射表中删除,从理论上减少比对时的查找次数。
谁shéi,又音shuí4。
读字读半边,这种例子有很多,比如“碡”,念成了“du”(正确的读音是 zhóu),“聒”念成了“gua”(正确的读音是 guō)
纯粹乱读,Safari 中有很多,比如“鼰”,念成了“nian”(正确的读音是 jú),“罉”,念成了“cang”(正确的读音是 chēng),“伝”,念成了“chuan”(正确的读音是 yún),“枡”,念成了“dou”(正确的读音是 shēng)
引用 @赵炎 的回复:
1、芎:《廣韻》去宮切,推導現代漢語 qiong1。
2、还有所谓“读字读半边”
2.1、碡本身就是多音字,有 du2、zhu2 两种读法,读 zhou2 显然是字典收录了白读音。
2.2、聒半边是耳和舌,请问哪半边读 gua?
3、纯粹乱读
3.1、伝就是傳,听说是纯粹乱读,应该读成 yun2
3.2、罉是方言词,读如 cang1,推导汉语 cheng1,这也算乱读?
开始正题。
在 ECMA-262 标准里的第 21.1.3.10 节5,说这个 String.prototype.localeCompare 需要按照 ECMA‑402 标准来实现。在 ECMA-402 标准里的 10.3.4 节Collator Compare Functions6里说,这个函数应由实现定义(The two Strings are compared in an implementation-defined fashion)。所以不如看代码。
先从不跨平台的浏览器开始。
Edge的Chakra里面调用的是Windows API CompareStringEx (lib/Runtime/Library/InJavascript/Intl.js#L868 -> lib/Runtime/Library/IntlEngineInterfaceExtensionObject.cpp#L1320)。刚才已经说过,Windows使用GB.*编码。
作者举例“有些多音字选择了不常见的读音,比如“沈”,在 Chrome 中是“chen”,而不是常见的“shen”,又比如“呵”,在 Safari 中念“a””,我们就用“沈”来做个测试。

按照原文说法,这个字就应该念“shen”。如图,因为GBK下按照拼音排序它就在“shen”这一带。

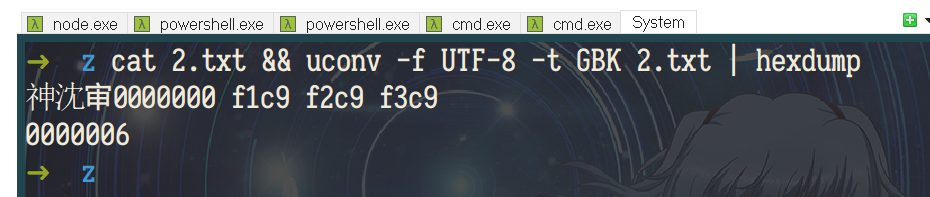
看完Edge,我们还是回到Chrome和Safari。作者说:“Chrome 的中文语言包制作者应该是一位在国外长大的中国人,Safari 的中文语言包制作应该是一位主修中文专业的外国人。”
嗯,事实证明,这根本不是什么“中文语言包”的锅,中文语言包根本不管这个……这锅,得推到 Unicode 头上。
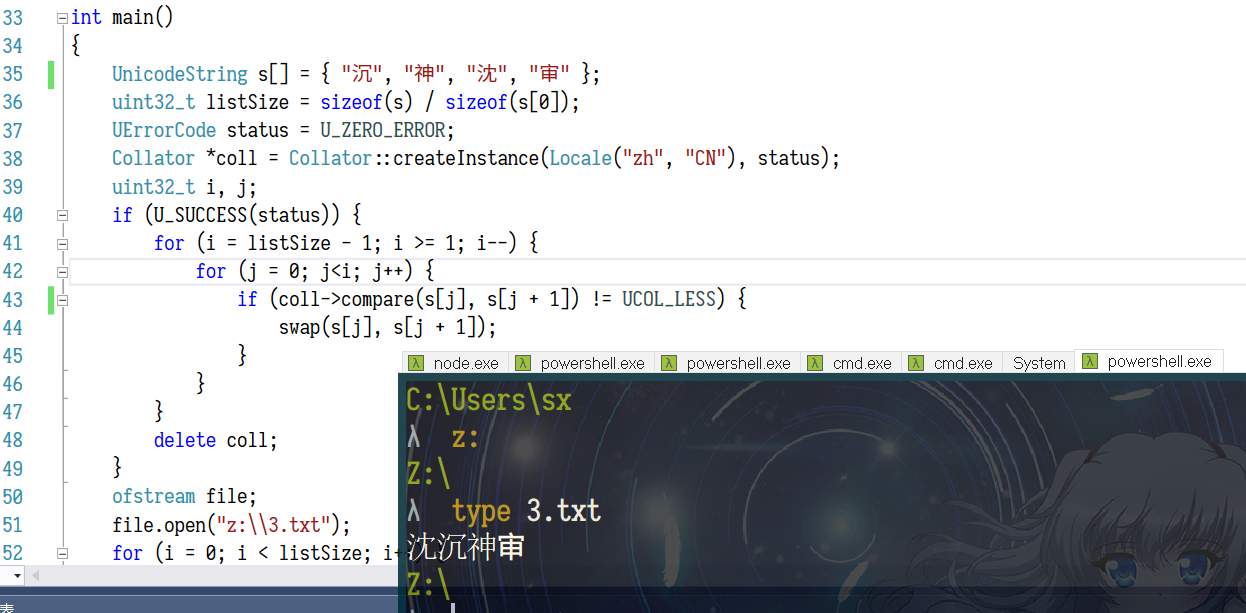
V8里面调用icu::compare两个UnicodeString(js/intl.js#2092 -> runtime/runtime-intl.cc#L638)。按照 ICU 的文档7,compare对标的就是CompareString这个Windows API,不过实际上他的效果还是有差距。以下代码即为一个演示,这就是按照作者的逻辑,“沈”在“沉”之前的原因。(不要在意代码缩进)
int main()
{
UnicodeString s[] = { "沉", "神", "沈", "审" };
uint32_t listSize = sizeof(s) / sizeof(s[0]);
UErrorCode status = U_ZERO_ERROR;
Collator *coll = Collator::createInstance(Locale("zh", "CN"), status);
uint32_t i, j;
if (U_SUCCESS(status)) {
for (i = listSize - 1; i >= 1; i--) {
for (j = 0; j<i; j++) {
if (coll->compare(s[j], s[j + 1]) != UCOL_LESS) {
swap(s[j], s[j + 1]);
}
}
}
delete coll;
}
ofstream file;
file.open("z:\\3.txt");
for (i = 0; i < listSize; i++) {
file << s[i] ;
}
file.close();
//std::cin.get();
return 0;
}
其在调用compare时,会转进到CollationCompare::compareUpToQuaternary,最后转进到reorder

reorder的内容是从reorderTable里面拿数据重新比较,而数据是从Collator::createInstance(Locale("zh", "CN"), status);这一行开始就已经读取了的。最后转进到zh.txt。

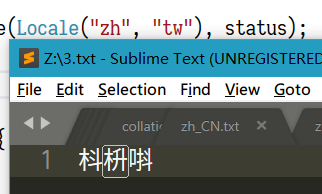
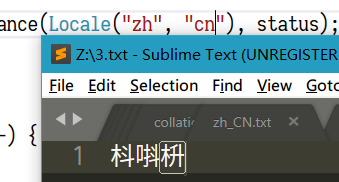
打开这个txt就会发现,如图所示。

这个“沈”在“pinyin”里就是摆在这个位置。作者说的念错音的“碡”“聒”也都可以看到是icu这个表的问题。然后,这个表的默认值是“pinyin”。
我们再看看 Safari,直接看 WebKit 里的 JavaScriptCore。懒得编译 WebKit,直接空口调代码。
有两个地方实现了 ECMA-402 的 10.3.4,一处在Source/JavaScriptCore/runtime/IntlCollatorPrototype.cpp#L106,还有一处在 Source/JavaScriptCore/runtime/IntlCollator.cpp#L415。不管怎么着,这俩调用的还是 ICU。
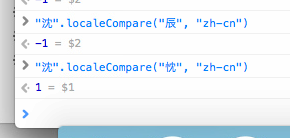
那为什么原作者说?“纯粹乱读,Safari 中有很多,比如“鼰”,念成了“nian”(正确的读音是 jú),“罉”,念成了“cang”(正确的读音是 chēng),“伝”,念成了“chuan”(正确的读音是 yún),“枡”,念成了“dou”(正确的读音是 shēng)”
也许是因为 Safari 用的不是 pinyin,而是 zhuyin。
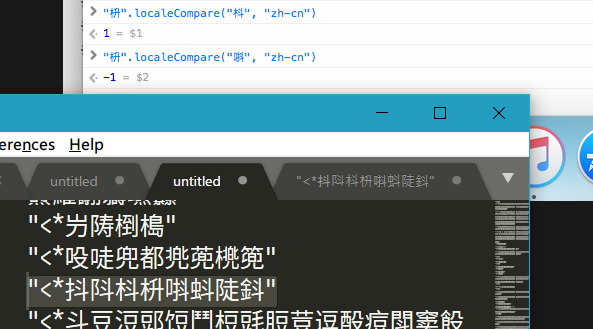
那为啥呢?排查了一下不是copyDefaultLocale()的问题,没调试器,不想查.jpg
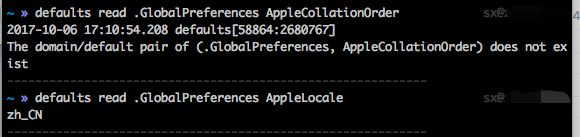
最后 Firefox。Firefox 的国际化处理也是用的 ICU,所以当然啦,它也一样……
……是不是忘了什么?
在前年,我被“𥊍”字坑过一次:https://blog.zsxsoft.com/post/16。这玩意和上面的字所在的平面都不同,属于中日韩统一表意文字扩充B的字符。在 ICU 的zh.txt里可没有这玩意哦。

事情的发展就变成这样了。
文末总结:
根据区域取得拼音不可靠。原因包括:
Edge 和 IE11 下只能取得 GB2312 的一级汉字的拼音。
Safari 使用了注音来排序,而不是拼音。
ICU 库只含有GBK字符,不含GB18030字符。
Chrome / Firefox使用的 ICU 库的拼音排序可能有毛病。
当然,只考虑Chrome+修复部分拼音的话,还是在一定意义上有用的。
参考资料:
[1] GB 18030-2000, 信息技术中文编码字符集[S].
[2] GB 2312-80, 信息交换用汉字编码字符集·基本集[S].
[3] 李宝安, 李燕, 孟庆昌.中文信息处理技术:原理与应用[M].北京:清华大学出版社,2005:26.
[4] 《普通话异读词审音表(修订稿)》征求意见公告[EB/OL].http://www.moe.edu.cn/jyb_xwfb/s248/201606/t20160606_248272.html.2016.
[5] ECMA-262, ECMAScript® 2017 Language Specification[S],2017:588.
[6] ECMA-402, ECMAScript® 2017 Internationalization API Specification[S],2017:49.
[7] ICU Project[EB/OL].http://userguide.icu-project.org/collation/api.

