
因过竹院逢僧话,偷得浮生半日闲。
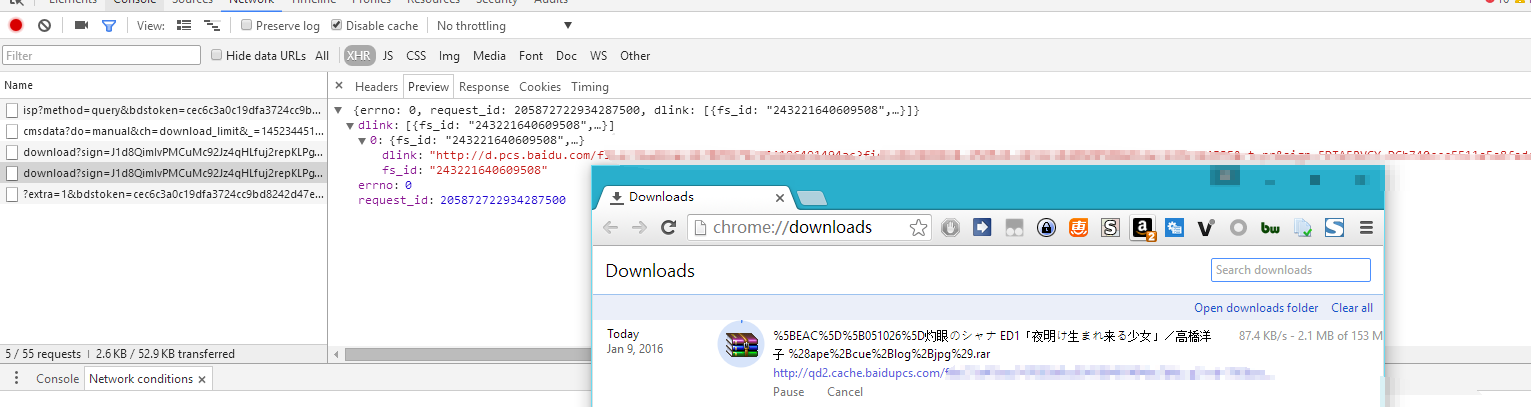
至今所见到的网盘的 HTTP 下载功能,比如百度云,实现都是极为简单的。无非是浏览器生成请求发给服务器,服务器发回一个下载地址,然后交给浏览器下载罢了。如下图所示:
相比之下,Mega.nz的上传和下载功能在这一众网盘中,显得极为出众。它可以在不安装任何浏览器插件的情况下,直接在 Web 页面内进行带进度条的、可暂停的上传与下载。

在浏览器内下载完成之后,创建真正的下载请求。然后浏览器以硬盘的最快写入速度写入文件,下载完成。

它怎么做到的?单步跟踪看看吧。
$(c + '.download-item').rebind('click', function(event) {
var c = $(event.target).attr('class');
if (c && c.indexOf('contains-submenu') > -1)
M.addDownload($.selected);
});首先,在右键下载的时候,用$.selected(即文件 ID )作为参数,呼叫下载函数。
this._later = setTimeout(function() {
queue.process(sp);
queue = undefined;
}, ms || 300);下载函数经过一系列的初始化处理后,转给DownloadQueue.prototype.push,这个函数往localStorage里写入下载文件的 ID 与下载时间。
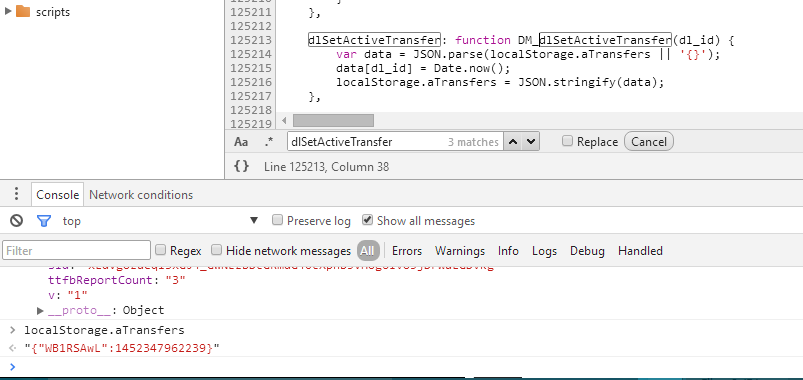
接着,把下载函数推到全局队列里。在这之前,下载函数根据 IO 的方式( Flash 或内存),显示不同的提示并初始化不同的下载器。
其队列使用setTimeout实现延时,每当往队列里推送一个元素时调用队头函数。
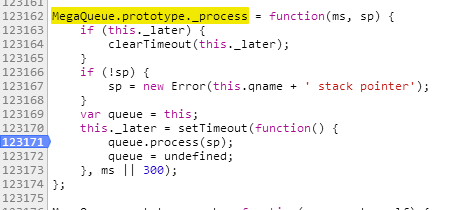
此时,队列启动下载部分的worker(并非Web Worker,自己实现的一个类而已)。worker向服务器发送一段请求。至于干嘛的我不知道,看上去是确定请求是否可以开始下载(从 quota 看来,也许是确定配额是否超标)。确定完成后,1000毫秒(Later)之后开始获取文件的下载地址。到这里,都与百度云等无二致。

拿到文件大小(字节)和文件地址后,开始对其进行分块切分。大致推测,是前 8 块按照首项为 128KB,每项公差为 128KB 的等差数列进行切分(即,第一块 128KB,第二块 256KB)。第八项之后,就按照 1MB 切分。估计是考虑到了小文件的缘故。
DownloadQueue.prototype.splitFile = function(dl_filesize) {
var dl_chunks = [];
var dl_chunksizes = {};
var p = 0;
var pp = 0;
for (var i = 1; i <= 8 && p < dl_filesize - i * 131072; i++) {
dl_chunksizes[p] = i * 131072;
dl_chunks.push(p);
pp = p;
p += dl_chunksizes[p];
}
var chunksize = dl_filesize / dlQueue._limit / 2;
if (chunksize > dlmanager.dlMaxChunkSize) {
chunksize = dlmanager.dlMaxChunkSize;
}
else if (chunksize <= 1048576) {
chunksize = 1048576;
}
else {
chunksize = 1048576 * Math.floor(chunksize / 1048576);
}
var reserved = dl_filesize - (chunksize * (dlQueue._limit - 1));
// var reserved = dl_filesize - chunksize;
// var eofcs = Math.max(Math.floor(chunksize/3),1048576);
while (p < dl_filesize) {
dl_chunksizes[p] = p > reserved ? 1048576 : chunksize;
// dl_chunksizes[p] = p > reserved ? eofcs : chunksize;
dl_chunks.push(p);
pp = p;
p += dl_chunksizes[p];
}
if (!(dl_chunksizes[pp] = dl_filesize - pp)) {
delete dl_chunksizes[pp];
delete dl_chunks[dl_chunks.length - 1];
}
dl_chunks = {
chunks: dl_chunks,
offsets: dl_chunksizes
};
if (d) {
dlmanager.logger.info('dl_chunks', chunksize, dl_chunks);
}
return dl_chunks;
}切分后,取URL,向队列推送下载的worker。每读一块,都把decrypter-worker推送到队列里解密,然后再扔给downloader-worker把解出来的东西往MemoryIO或FlashIO扔。全搞完后,下载,完成。
那,MemoryIO是怎么实现的?
看MemoryIO.setCredentials函数,内有一行
dblob = msie ? new MSBlobBuilder() : [];看write函数
if (msie) {
dblob.append(have_ab ? buffer : buffer.buffer);
}
else {
dblob.push(new Blob([buffer]));
}可推得,其在 IE10+ 用BlobBuilder实现,在其它浏览器用数组+ Blob 实现。至于为啥针对IE特殊使用Blob,谁知道呢……根据 MDN,BlobBuilder应该反而是被废弃的东西(https://developer.mozilla.org/zh-CN/docs/Web/API/Blob)……
最后,调用download函数。其实现如下:
this.download = function(name, path) {
var blob = this.getBlob();
this.completed = true;
if (is_chrome_firefox) {
requestFileSystem(0, blob.size, function(fs) {
var opt = {
create: !0,
fxo: dl
};
fs.root.getFile(dl_id, opt, function(fe) {
fe.createWriter(function(fw) {
fw.onwriteend = fe.toURL.bind(fe);
fw.write(blob);
});
});
});
}
else if (msie) {
navigator.msSaveOrOpenBlob(blob, name);
}
else {
var blob_url = myURL.createObjectURL(blob);
var dlLinkNode = document.getElementById('dllink');
dlLinkNode.download = name;
dlLinkNode.href = blob_url;
dlLinkNode.click();
Later(function() {
myURL.revokeObjectURL(blob_url);
blob_url = undefined;
});
}
this.abort();
};is_chrome_firefox的定义如下:
var is_chrome_firefox = document.location.protocol === 'chrome:'
&& document.location.host === 'mega' || document.location.protocol === 'mega:';推断,其是检测是否在本地环境下运行。也就是说,第一个判断,若在其 native app 环境下访问,就调用LocalFileSystem API。如果非IE,就把blob url写入一个链接后,模拟点击链接进行保存。至于IE,根据这篇文章(http://stackoverflow.com/questions/24007073/open-links-made-by-createobjecturl-in-ie11)所言,似乎因为安全问题不允许直接使用 blob 保存,只能使用私有 API(https://msdn.microsoft.com/en-us/library/hh779016(v=vs.85).aspx)。
这个MemoryIO有什么限制呢?也是有的。
根据 Chromium 社区反馈(https://code.google.com/p/chromium/issues/detail?id=375297),Blob 的大小不能超过500MB,故fileSizeLimit被强制限制为496MB。不过说句老实话,一般用户看到浏览器占这么大内存早就炸了吧(反正某网盘不怕,100MB 就不让用浏览器下载,用客户端不开VIP还限速……)
嗯,大概就是这样吧。


